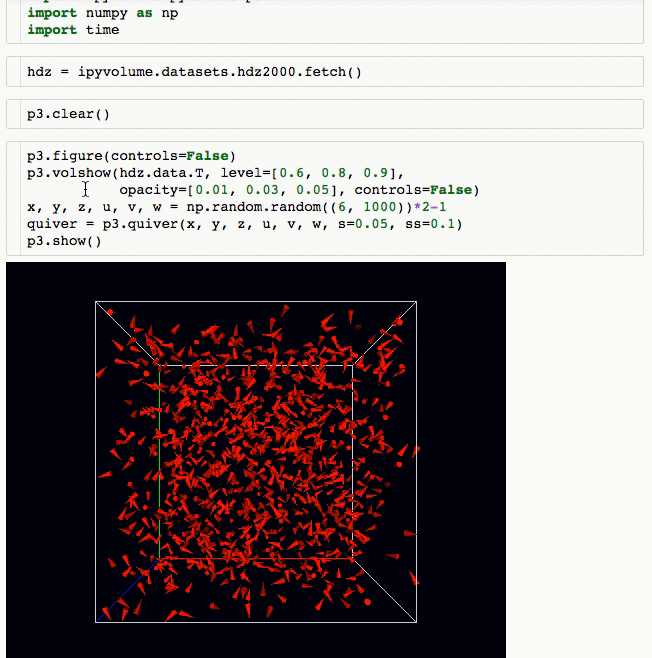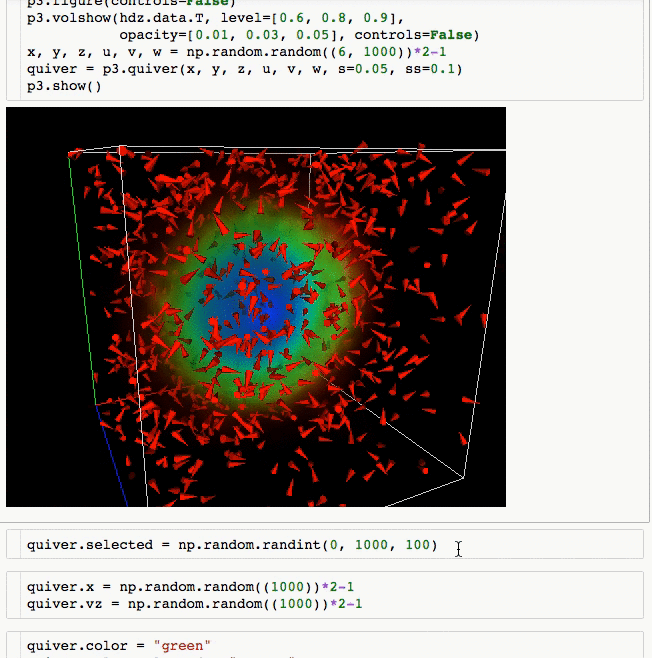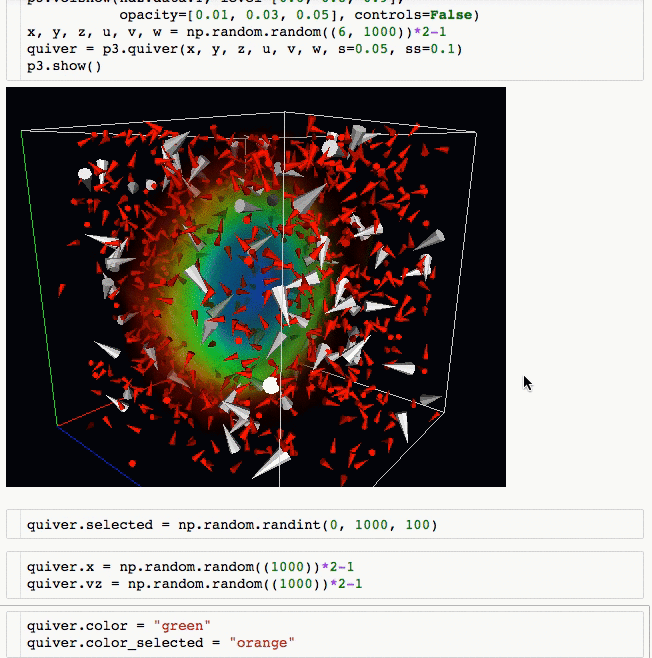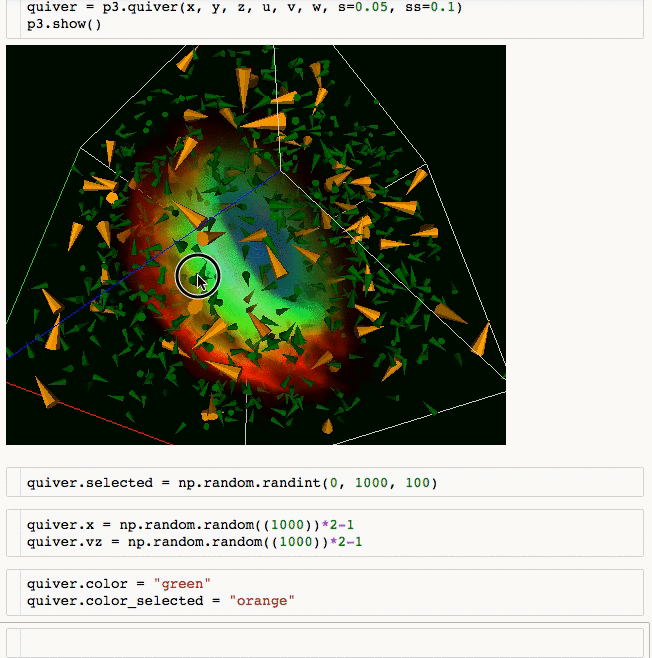
Laravel is a web application framework with expressive, elegant syntax. We believe development must be an enjoyable and creative experience to be truly fulfilling. Laravel attempts to take the pain out of development by easing common tasks used in the majority of web projects, such as:
Laravel is accessible, yet powerful, providing tools needed for large, robust applications.
Learning Laravel
Laravel has the most extensive and thorough documentation and video tutorial library of any modern web application framework, making it a breeze to get started learning the framework.
If you’re not in the mood to read, Laracasts contains over 1100 video tutorials on a range of topics including Laravel, modern PHP, unit testing, JavaScript, and more. Boost the skill level of yourself and your entire team by digging into our comprehensive video library.
Laravel Sponsors
We would like to extend our thanks to the following sponsors for helping fund on-going Laravel development. If you are interested in becoming a sponsor, please visit the Laravel Patreon page:
Thank you for considering contributing to the Laravel framework! The contribution guide can be found in the Laravel documentation.
Security Vulnerabilities
If you discover a security vulnerability within Laravel, please send an e-mail to Taylor Otwell via taylor@laravel.com. All security vulnerabilities will be promptly addressed.
License
The Laravel framework is open-sourced software licensed under the MIT license.
As for case [2] above, a word embedding matrix is trained while training each end-to-end DNN model.
Japanese BERT
I used bert-japanese implemented by “yoheikikuta”.
Instead of using the trained SentencePiece and the pratrained BERT model, I trained them from scratch, only a few changes are listed below.
I trained SentencePiece with 8,000 words instead of 32,000.
I used newer Japanese Wikipedia dataset than the one he used.
I pretrained BERT model up to 1,300,000 steps instead of 1,400,000.
The pretrained result is shown as below.
The best model among the 7 models above is CNN with Sentence Piece.
Results may be changed if you do more complicated classification tasks.
For each DNN model tested on both MeCab and Sentence Piece, such as MLP, CNN or biLSTM, a model that used Sentence Piece outperformed the one that used fastText+MeCab+ipadicNEologd.
Letmeask is a web application to create interactive Q&A rooms to help streamers/content creators. The project was developed during Next Level Week #06 Together (ReactJS), event presented by Rocketseat.
To complement the project I developed: toast notifications, logout flow, room reopen flow, listing of user rooms, permission rules for accessing links, interaction rules with the room and others fixes.
Technologies
This project was developed using the following technologies:
Clone the repository git clone https://github.com/rafaelthz/letmeask-nlw6.git
Access the folder cd letmeask-nlw6
Install the dependencies with yarn
Create a .env.local file and add the yours Firebase SDK configs – see more on the docs
Start the server with yarn start
Now you can access localhost:3000 in your browser.
Remembering that it will be necessary to create an account in Firebase and a project to make a Realtime Database available.
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
We propose COPA, the first unified framework for certifying robust policies for general offline RL against poisoning attacks, based on certification criteria including per-state action stability and the lower bound of cumulative reward. Specifically, we propose new partition and aggregation protocols (PARL, TPARL, DPARL) to obtain robust policies and provide certification methods for them. More details can be found in our paper:
Fan Wu*, Linyi Li*, Chejian Xu, Huan Zhang, Bhavya Kailkhura, Krishnaram Kenthapadi, Ding Zhao, and Bo Li, “COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks”, ICLR 2022 (*Equal contribution)
In our paper, we conduct experiments on Atari games Freeway and Breakout, as well as an autonomous driving environment Highway. For each RL environment, we evaluate three RL algorithms (DQN, QR-DQN, and C51), three aggregation protocols and certification methods (PARL, TPARL, and DPARL), up to three partition numbers, and multiple horizon lengths.
@inproceedings{wu2022copa,
title={COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks},
author={Wu, Fan and Li, Linyi and Xu, Chejian and Zhang, Huan and Kailkhura, Bhavya and Kenthapadi, Krishnaram and Zhao, Ding and Li, Bo},
booktitle={International Conference on Learning Representations},
year={2022}
}
An iterator is stateful. You can have multiple iterators without any impact on each other, but make sure to synchronize access to them and the tree in a concurrent environment.
Caution! Next panics if there is no next element. Make sure to test for the next element with HasNext before.
Use cases
When you want to use []byte as a key in the map.
When you want to iterate over keys in map in sorted order.
Limitations
Caution! To guarantee that the B+ tree properties are not violated, keys are copied.
You should clearly understand what []byte slice is and why it is dangerous to use it as a key. Go language authors do prohibit using byte slice ([]byte) as a map key for a reason. The point is that you can change the values of the key and thus violate the invariants of map:
// if it worked b:= []byte{1}
m:=make(map[[]byte]int)
m[b] =1b[0] =2// it would violate the invariants m[[]byte{1}] // what do you expect to receive?
So to make sure that this situation does not occur in the tree, the key is copied byte by byte.
Benchmark
Regular Go map is as twice faster for put and get than B+ tree. But if you
need to iterate over keys in sorted order, the picture is slightly different:
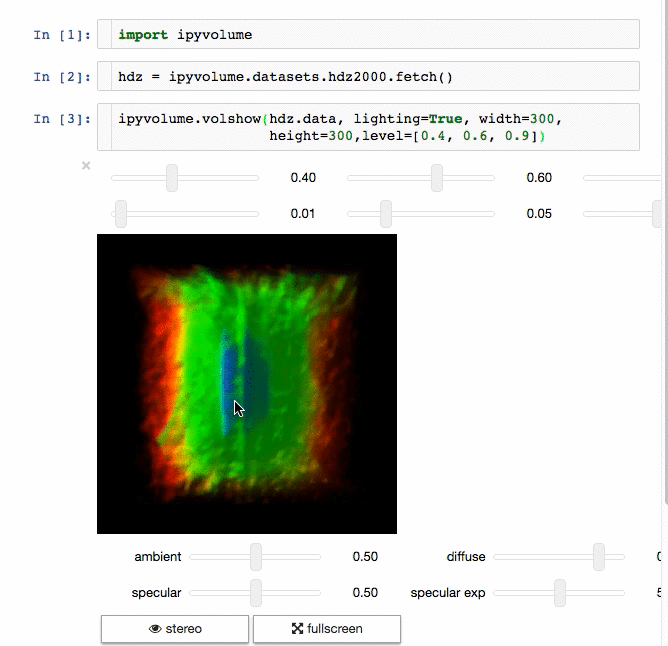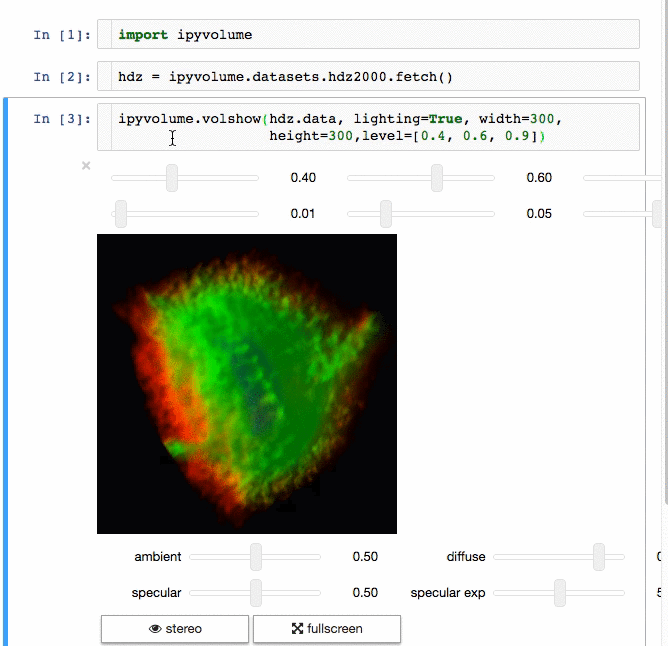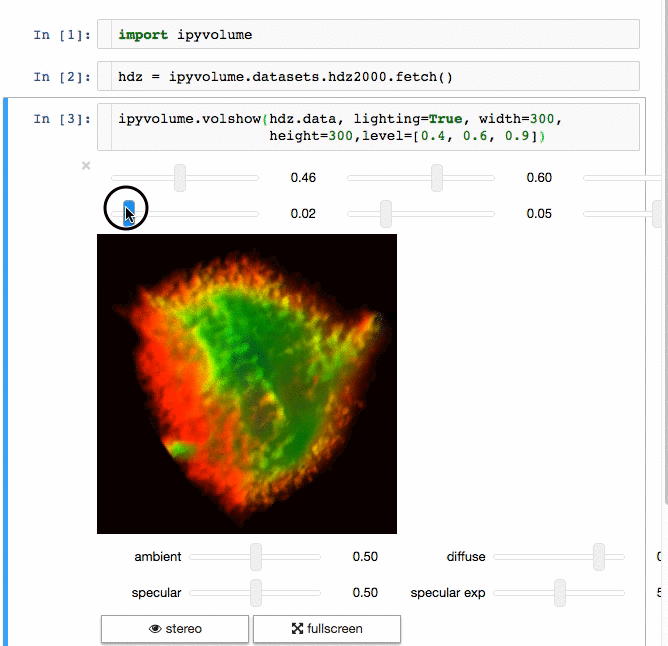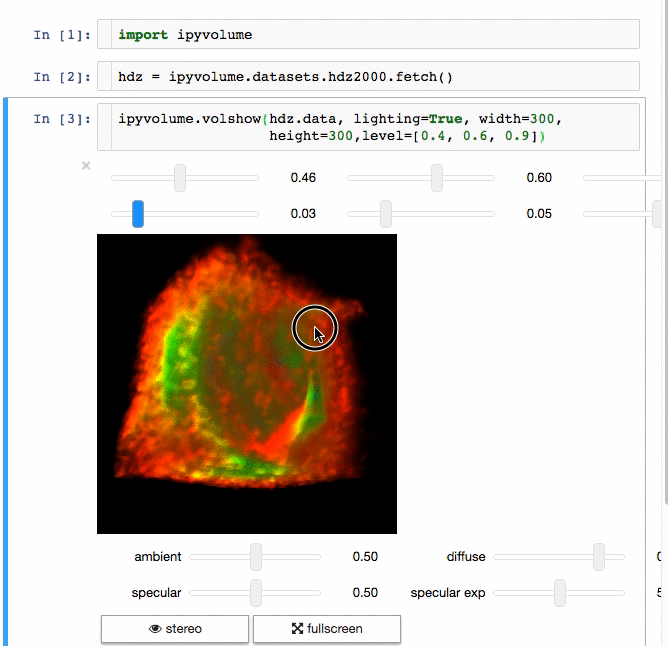
If you want to use Jupyter Lab, please use version 3.0.
Using pip
Advice: Make sure you use conda or virtualenv. If you are not a root user and want to use the --user argument for pip, you expose the installation to all python environments, which is a bad practice, make sure you know what you are doing.
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume
Pre-notebook 5.3
If you are still using an old notebook version, ipyvolume and its dependend extension (widgetsnbextension) need to be enabled manually. If unsure, check which extensions are enabled:
You have been warned, do this only if you know what you are doing, this might hunt you in the future, and now is a good time to consider learning virtualenv or conda.
If you want to use Jupyter Lab, please use version 3.0.
Using pip
Advice: Make sure you use conda or virtualenv. If you are not a root user and want to use the --user argument for pip, you expose the installation to all python environments, which is a bad practice, make sure you know what you are doing.
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume
Pre-notebook 5.3
If you are still using an old notebook version, ipyvolume and its dependend extension (widgetsnbextension) need to be enabled manually. If unsure, check which extensions are enabled:
You have been warned, do this only if you know what you are doing, this might hunt you in the future, and now is a good time to consider learning virtualenv or conda.
This repository is the portal for the course “Unemployment” taught by Pascal Michaillat at UC Santa Cruz. The course ID is ECON 182. The course portal contains the syllabus, provides a discussion forum, and hosts other course resources.
Lecture handouts – The folder contains handouts distributed in lecture. The handouts are designed to help you develop your research ideas and collect questions about the lecture videos.
Discussion forum – This collaborative discussion forum is designed to get you help quickly and efficiently. You can ask and answer questions, share updates, have open-ended conversations, and follow along course announcements.
Reading material – The folder contains book chapters and articles that may be hard to find online.
Lecture material – The folder contains discussions from lecture.
Presentations – The folder contains all the student presentations given during the quarter, and some presentation templates and examples.
LaTeX code for presentation slides – Complete code to produce a presentation with LaTeX. Just upload the files to Overleaf and start writing your slides!
LaTeX code for research paper – Complete code to produce a research paper with LaTeX. Just upload the files to Overleaf and start writing your paper!
TLDR; Text extraction, transcription, punctuation restoration, translation, summarization and text to speech
The goal of this project is to extend the functionalities of Fabric. I’m particularly interested in building pipelines using utilities like yt as a source and chaining them with the | operator in CI.
However, a major limitation exists: all operations are constrained by the LLM context. For extracting information from books, lengthy documents, or long video transcripts, content may get truncated.
To address this, I started working on adding a summarization step before applying a fabric template, based on the document length.
Additionally, I explored capabilities like transcripting, translating and listening to the pipeline result or saving it as an audio file for later consumption.
Examples
Listen to the condensed summary of a long Youtube video
tp accepts unformatted content, such as automatically generated YouTube transcripts. If the text lacks punctuation, it restores it before further processing, which is necessary for chunking and text-to-speech operations.
Transcription
Converts audio and video files to text using Whisper.
Summarization
The primary aim is to summarize books, large documents, or long video transcripts using an LLM with an 8K context size. Various summarization levels are available:
Extended Bullet Summary (--ebullets, --eb )
Splits text into chunks.
Summarizes all chunks as bullet points.
Concatenates all bullet summaries.
The goal is to retain as much information as possible.
Condensed Bullet Summary (--cbullets, --cb)
Executes as many extended bullet summary phases as needed to end up with a bullet summary smaller than an LLM context size.
Textual Summary (--text, --t)
A simple summarization that does not rely on bullet points.
Translation (--translate, --tr)
Translates the output text to the desired language.
Use two letters code such as en or fr.
Usage
usage: tp [-h] [--ebullets] [--cbullets] [--text] [--lang LANG] [--translate TRANSLATE] [--output_text_file_path OUTPUT_TEXT_FILE_PATH] [text_or_path]
tp (text processing) provides transcription, punctuation restoration, translation and summarization from stdin, text, url, or file path. Supported file formats are: .aiff, .bmp, .cs, .csv, .doc, .docx, .eml, .epub, .flac, .gif, .htm, .html, .jpeg, .jpg, .json, .log, .md, .mkv, .mobi, .mp3, .mp4, .msg, .odt, .ogg, .pdf, .png, .pptx, .ps, .psv, .py, .rtf, .sql, .tff, .tif, .tiff, .tsv, .txt, .wav, .xls, .xlsx
positional arguments:
text_or_path plain text; file path; file url
options:
-h, --help show this help message and exit
--ebullets, --eb Output an extended bullet summary
--cbullets, --cb Output a condensed bullet summary
--text, --t Output a textual summary
--lang LANG, --l LANG
Forced processing language. Disables the automatic detection.
--translate TRANSLATE, --tr TRANSLATE
Language to translate to
--output_text_file_path OUTPUT_TEXT_FILE_PATH, --o OUTPUT_TEXT_FILE_PATH
output text file path
Text To Speech (tts)
Listen to the pipeline result or save it as an audio file to listen later.
tts can also read text files, automatically detecting their language.
usage: tts.py [-h] [--output_file_path OUTPUT_FILE_PATH] [--lang LANG] [input_text_or_path]
tts (text to speech) reads text aloud or to mp3 file
positional arguments:
input_text_or_path Text to read or path of the text file to read.
options:
-h, --help show this help message and exit
--output_file_path OUTPUT_FILE_PATH, --o OUTPUT_FILE_PATH
Output file path. If none, read aloud.
--lang LANG, --l LANG
Forced language. Uses language detection if not provided.
constTimer=require('tiny-timer')consttimer=newTimer()timer.on('tick',(ms)=>console.log('tick',ms))timer.on('done',()=>console.log('done!'))timer.on('statusChanged',(status)=>console.log('status:',status))timer.start(5000)// run for 5 seconds
Usage
timer = new Timer({ interval: 1000, stopwatch: false })
Optionally set the refresh interval in ms, or stopwatch mode instead of countdown.
timer.start(duration [, interval]) {
Starts timer running for a duration specified in ms.
Optionally override the default refresh interval in ms.
timer.stop()
Stops timer.
timer.pause()
Pauses timer.
timer.resume()
Resumes timer.
Events
timer.on('tick', (ms) => {})
Event emitted every interval with the current time in ms.
timer.on('done', () => {})
Event emitted when the timer reaches the duration set by calling timer.start().
timer.on('statusChanged', (status) => {})
Event emitted when the timer status changes.
Properties
timer.time
Gets the current time in ms.
timer.duration
Gets the total duration the timer is running for in ms.
timer.status
Gets the current status of the timer as a string: running, paused or stopped.









 https://github.com/KKOA/test-project
https://github.com/KKOA/test-project